This post provides you with the list of User Shell Folders in Windows 10/11 and their default paths. If you’ve moved a shell folder earlier, you can restore it to the default location via the folder properties Location tab in most cases.
However, there are situations where the Location tab option can’t be used — i.e. when two special folders such as Music and Videos become merged and point to the same location. In that case, clicking Restore Default in the folder properties Location tab causes an error.
In such cases, resetting the respective shell folder path(s) in the registry is the only possible solution. This article provides the .reg files needed to revert to the default shell folder paths quickly and also includes the list of shell folders and their default path for your reference. This article applies to Windows 10 and Windows 11.
Reset Shell Folder Paths to Default using Registry files
- w10_usf_defaults_hkcu.zip – Windows 10/11 Shell Folder Reset defaults for HKCU*
- w10_usf_defaults_hklm.zip – Windows 10/11 Shell Folder Reset defaults for HKLM*
- w10_usf_clear_override_hkcu.zip – Windows 10/11 Clear the Overriding registry values for HKCU (See Table 2)
* HKCU is short for HKEY_CURRENT_USER & HKLM is HKEY_LOCAL_MACHINE
List of Shell folders & their default locations in Windows 10/11
User Shell Folders (Per-user)
For the current user account, the special folder paths are stored in the following registry key:
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\User Shell Folders
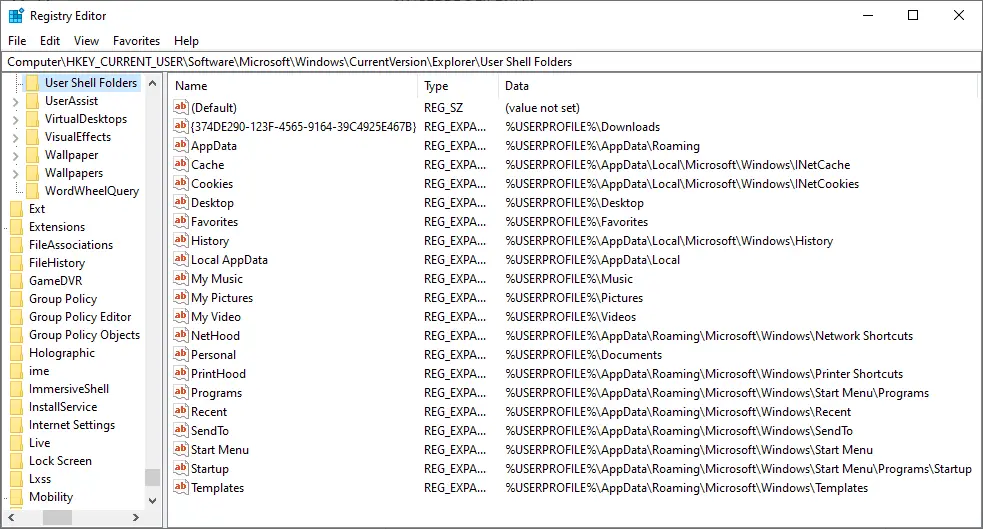
| Shell Folder Name (Value type: REG_EXPAND_SZ) | Location |
| {374DE290-123F-4565-9164-39C4925E467B} | %USERPROFILE%\Downloads |
| AppData | %USERPROFILE%\AppData\Roaming |
| Cache | %USERPROFILE%\AppData\Local\Microsoft\Windows\INetCache |
| Cookies | %USERPROFILE%\AppData\Local\Microsoft\Windows\INetCookies |
| Desktop | %USERPROFILE%\Desktop |
| Favorites | %USERPROFILE%\Favorites |
| History | %USERPROFILE%\AppData\Local\Microsoft\Windows\History |
| Local AppData | %USERPROFILE%\AppData\Local |
| My Music | %USERPROFILE%\Music |
| My Pictures | %USERPROFILE%\Pictures |
| My Video | %USERPROFILE%\Videos |
| NetHood | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Network Shortcuts |
| Personal | %USERPROFILE%\Documents |
| PrintHood | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Printer Shortcuts |
| Programs | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Start Menu\Programs |
| Recent | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Recent |
| SendTo | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\SendTo |
| Start Menu | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Start Menu |
| Startup | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup |
| Templates | %USERPROFILE%\AppData\Roaming\Microsoft\Windows\Templates |
Note: {374DE290-123F-4565-9164-39C4925E467B} represents the Downloads folder.
Overriding registry values
The following items do not exist in a clean install of Windows 10 and Windows 11. They’re created only if you redirect those folders to Microsoft OneDrive or DropBox. If the following values exist, the location defined in the following values takes precedence. In case of any conflict, the following values can be deleted so that the defaults (above) are used.
To clear or reset to defaults all of these values below, download w10_usf_clear_override_hkcu.zip.
Logoff and login back for the change to take effect.
| Value Name (Overrides) | Shell folder whose path is Overridden |
| {3B193882-D3AD-4EAB-965A-69829D1FB59F} | Saved Pictures |
| {AB5FB87B-7CE2-4F83-915D-550846C9537B} | Camera Roll |
| {B7BEDE81-DF94-4682-A7D8-57A52620B86F} | Screenshots |
| {F42EE2D3-909F-4907-8871-4C22FC0BF756} | Local Documents |
| {7D83EE9B-2244-4E70-B1F5-5393042AF1E4} | Local Downloads |
| {A0C69A99-21C8-4671-8703-7934162FCF1D} | Local Music |
| {0DDD015D-B06C-45D5-8C4C-F59713854639} | Local Pictures |
| {35286A68-3C57-41A1-BBB1-0EAE73D76C95} | Local Videos |
| {24D89E24-2F19-4534-9DDE-6A6671FBB8FE} | OneDrive Documents |
| {767E6811-49CB-4273-87C2-20F355E1085B} | OneDrive Camera Roll |
| {31C0DD25-9439-4F12-BF41-7FF4EDA38722} | 3D Objects |
| {754AC886-DF64-4CBA-86B5-F7FBF4FBCEF5} | Desktop |
User Shell Folders (Per-system)
The common special folder (applicable for all users) paths are stored in the following registry key:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\User Shell Folders
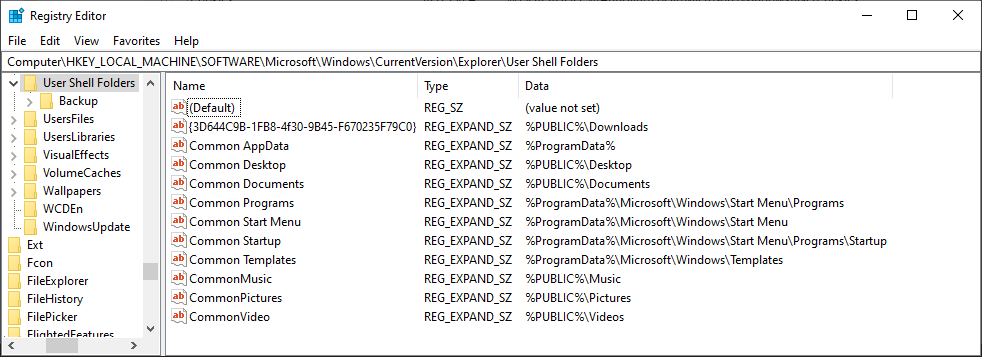
| Shell Folder Name — Value type: REG_EXPAND_SZ | Location |
| {3D644C9B-1FB8-4f30-9B45-F670235F79C0} | %PUBLIC%\Downloads |
| Common AppData | %ProgramData% |
| Common Desktop | %PUBLIC%\Desktop |
| Common Documents | %PUBLIC%\Documents |
| Common Programs | %ProgramData%\Microsoft\Windows\Start Menu\Programs |
| Common Start Menu | %ProgramData%\Microsoft\Windows\Start Menu |
| Common Startup | %ProgramData%\Microsoft\Windows\Start Menu\Programs\Startup |
| Common Templates | %ProgramData%\Microsoft\Windows\Templates |
| CommonMusic | %PUBLIC%\Music |
| CommonPictures | %PUBLIC%\Pictures |
| CommonVideo | %PUBLIC%\Videos |
Note:
{3D644C9B-1FB8-4f30-9B45-F670235F79C0}value represents the Public Downloads folder.- The values
CommonMusic,CommonPictures,CommonVideoare single words (no space in them.)
RELATED: [Fix] Accidentally Merged Music, Pictures, Videos or Downloads Folders
(Last reviewed on July 28, 2022. Last tested on Windows 10 v21H2 and Windows 11 v21H2.)
One small request: If you liked this post, please share this?
One "tiny" share from you would seriously help a lot with the growth of this blog. Some great suggestions:- Pin it!
- Share it to your favorite blog + Facebook, Reddit
- Tweet it!
Thanks, it was driving me crazy. Documents and Pictures were pointing to OneDrive even if OneDrive was configured to save to This PC.
The guilty registry keys were the ones with GUID name for Local Documents and Local Pictures had a path %USERPROFILE%\OneDrive\Documents. I removed OneDrive from the path and I could see again my local folder.
During all this, I could see my local folder only through Libraries or by browsing directly to C:\Users\abc\Documents.
Thanks again.
Thanks for your information.. it worked for me 🙂
Fantastic, you solved “the problem” in one single run. Thank you!
Ramesh,
I utilized, “PC Mover,” for a new Windows migration a year ago. During the cleanup process something happened (I’m not sure if it was me or the application) and it the “Downloads” folder began to mimick the “Documents” folder. I almost gave up trying to find a solution until I tried your registry key update, “w10_usf_clear_override_hkcu.zip.” It resolved the issue!
Thank you!
{31C0DD25-9439-4F12-BF41-7FF4EDA38722} Is 3D Objects if anyone needed help with that.
Thank you!! Was looking everywhere for that key. Stupid Win10 Update-2004 decided to merge 3D Objects and My Videos into the root of my %USERPROFILE% . Ugh! Such a mess.
Worked for me as well. What a monumental pain in the rear the MS OS’s have become with all the embedding. Did the same as the first reply and then redirected to desired location. Thanks
Aug 23 2019 Thank you! File 3 worked for me.
this article makes no sense. “download these files, this is where things are supposed to be, log off and log back on” are the only instructions. when i download the files, do i extract them? do i open them and do anything in them? do i leave them, try to restore my folders and then restart my computer? it makes NO sense. i definitely need step-by-step, detailed instructions.
If you need detailed step by step instructions then you probably shouldn’t be messing with the registry. Entitled much?
1.) READ THE KEYS FIRST!
2.) Back up your registry with a restore point
3.) Open File Explorer (Win+E), and navigate to the location of the .reg file you want to import. 4.) Right click on the .reg file, and click on Merge menu Item.
5.) When you import (merge) a .reg file, it will overwrite and replace the current key (s) and data value (s) in your registry with the contents of the .reg file.
NOTE: Messing with the Registry is risky
Bonjour,
Vraiment un très grand merci pour votre travail.
Grâce à lui j’ai pu résoudre un problème récurrent qu’aucune autre solution ne m’avait permis de résoudre, c’est à dire la réinitialisation par défauts de hkcu.
Merci encore et bonne continuation
Laurent
Thank you very much!!!!
Thank you, your instructions were quite sufficient and I have resolved the problem of OneDrive dominance over my Documents. You have saved my sanity 🙂
Excellent write up! Thank you, this resolved the issue for me!
Thank you for this article. I was not aware that OneDrive started taking over the syncing of personal folders. This could be helpful to some people so I understand why they would do it, but then I could not use the Desktop as a temporary storage for files I was working on. I will recommend this tip far and wide.
Most helpful post – thanks alot.
One Drive had introduced another Documents folder and I had moved it to my USER folder, i.e. C:\Users\Mine01 by mistake/tiredness INSTEAD of C:\Users\Documents.
After that I didn’t know what to do because nothing was allowed, due to self referencing folder(s) and disallowed Renames etc.
Your Registry Reset did the trick
Muito Obrigado por ter postado estas chaves de registro. Realmente resolveu o problema que eu tinha de as pastas do Este Computador (Documentos, Imagens, Músicas e Vídeos) estarem todas mescladas (no mesmo destino e com o mesmo nome). Para resolver, é só baixar os arquivos de registro postados acima e executa-los. Depois e só reiniciar o computador que as pastas voltarão ao normal.
Translated to English (by Google Translator)
“Thank you very much for posting these registration keys. It really solved the problem that I had of the folders of This Computer (Documents, Images, Music and Videos) were all merged (in the same destination and with the same name). To resolve, just download the log files posted above and run them. Then and just restart the computer the folders will return to normal.”
Thanks Ramesh – this worked for me in untangling my Documents folder from OneDrive. I appreciate you spending the time to post a solution.
I am trying to redirect user downloads folders to their OneDrive, but my script runs as a system account. Is there a way to get the HKCU paths of these folders without user context?
Thank you so much, OneDrive was driving me out of the Windows.
Thanks for teaching me about the User Shell Folders, for current user and local machine. I was able to fix my libraries, which were mislabeled and pointing to the wrong files. Finally, a real solution here! Awesome.
Thank you Thank you! This type of thing from Microsoft really makes me hate computers and technology. If I wanted something this far up my ass I would go to the s__ shop. They really need to stop forcing this intrusive layering of unnecessarily complicated services. Microsoft head my words, with great power come great responsibility and you guys are abusing your position and leverage.
Could you please help me to backup only documents to OneDrive through GPO.
currently i have made the setup which is taking backup of all files.
we really want to backup only document folder.
so please suggest how to exclude other two folders, Desktop and Pictures.
Thank you so much for making this. I accidentally engaged Onedrive and it completely screwed over some of the things I use as they do not allow access to Onedrive folders.
a Perfect fix for a maddening problem, in the past I’ve had to format & reinstall out of frustration with One Drive redirection.
Thank you so much for this.
These reg keys now have a permanent home in my tech tools.
thank you so much. this worked
Trying to restore my User System Folders was driving me crazy. Nothing seemed to work until I found your article and used your
“reset to defaults all of these values below, download w10_usf_clear_override_hkcu.zip. Logoff and login back for the change to take effect”
It worked billiantly…every folder back to original status and synced.
Thank you so much.
Worked great- twice! Thanks for all the file details-
The day is saved. Thankyou! I was really wracking my brain over why the file paths refused to change, even after editing the registry keys. Deleting the additional/conflicting ones fixed the problem.
What about {754AC886-DF64-4CBA-86B5-F7FBF4FBCEF5}?
It’s a second entry for “Desktop. Is it also like the other “Local” version of the folders, as per Table 2?
@coch: Yes. {754AC886-DF64-4CBA-86B5-F7FBF4FBCEF5} is another entry for Desktop. This value need not exist.
{24D89E24-2F19-4534-9DDE-6A6671FBB8FE} wats dat?
{24D89E24-2F19-4534-9DDE-6A6671FBB8FE} is another GUID for “Documents”. I believe OneDrive uses this GUID.
Worked 10/10
Thank you!!
Thanks, this helped.